





Writing web apps these days is not trivial. There are way many technologies involved. It can get overwhelming and the complexity can get out of control quickly.
I wanted to write about this for a while now. I am about to release a little app I wrote. It solves the classic problem of: I want to share sensitive data with someone (some message) and I want to remote it once the recipient has seen it. I don't them to have to install apps or share their handles with me. I want to share the message quickly and securely.
I have written other web tools and today I'd like to discuss the stack I have used both for the writing the app and also for solving all the operational tasks. A bit of churn with that last one.
The type of web apps I am talking about have a simple logic and require some sort of authentication and persistence. Over the last year I have changed my mind regarding what tech stack to use for building these type of web apps. I was in the single page app (SPA) camp for a while but I believe server side rendering (SSR) is totally valid for most apps. Specially this type of simple apps. At this point I'd like to mention htmx. This is a javascript library that allows you to do things like this in your code (from the htmx docs):
<button
hx-post="/clicked"
hx-trigger="click"
hx-target="#parent-div"
hx-swap="outerHTML"
>
Click Me!
</button>
If you load htmx (javascript library) it will see that the button element has some "hx" attributes and it will fire an http post request to the server using the "/clicked" path. htmx will use whatever the server returns to replace the contents of the element with id "parent-div". This paradigm allows you to have a more snappy UI interactions that you may think you needed SPAs for.
Here is an example of htmx for some UI interactions I have in the admin portion of my blog. Instead of having to navigate to another page to save the contents of a blog post, I update it via htmx so I can stay editing the post:
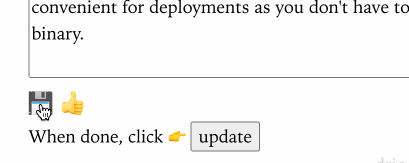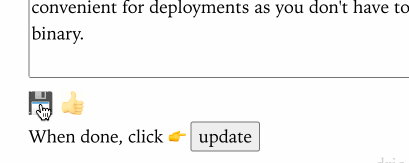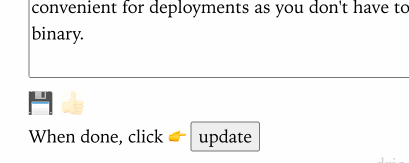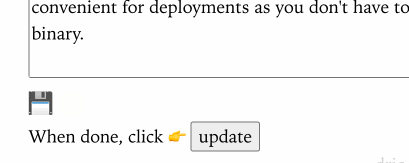
SPA like UI interactions for the admin backend of this site using htmx.
My programming language of choice for the backend is golang. There are many reasons for that: speed, single binary deployments and a great standard library. I use the chi router to write the endpoint's logic.
For persistence I use sqlite. It is a joy to use and reduces the operational churn dramatically. You may be asking, but how do you do high availability (HA)? Well, I don't. For most of the apps I am building right now I do not need HA. It just complicates things. An hour or two of downtime is fine. I will deal with it if the moment arrives. I use this driver that is cgo free. That is very convenient for deployments as you don't have to compile the sqlite c piece into the golang binary.
I create a go module for the application. All the code files belong to the main package. I typically have three files: main.go, db.go and server.go (plus server_test.go). In the main.go file I have some config defaults, and create or open the sqlite file that will contain my database. I then use a function to create a model, which is a struct that contains a reference to the sql db driver. I then create all the methods I need to satisfy an interface that defines the API of anything I need to interact with the DB.
Back in main.go, I have another function that creates a server. The server is another struct that packs together all the different components of the app, among them: the model, a logger, the server router (chi), and a few other variables like the app name, port, domain, etc... In this function I also tell chi I want to serve static files, add the api routes and templates. The serve.go also has all the methods that implement the handlers for the endpoints. Chi is my favorite router for go. It has zero dependencies and it is very expressive. I highly recommend it.
At this point I can start the server.
For this type of apps I tend to do end to end testing. This would not be possible if I used a networking based sql engine. But with sqlite, I can point my model to an in memory db and pass that to the server for testing. With the help of httptest we can write our end to end tests and they will run blazing fast.
Now it is time to deploy your app. For a long time I have been using an ec2 instance that I manage. It is ok, but the list of things you have to take care of is not insignificant. First you need a webserver to server different apps. Caddy is great, but you still have to configure it, run it and update it periodically. Then you need to create services for your go app. Yes, if you use docker, docker will take care of that for you. Then you have to keep the OS up to date. Then you have to write some scripts to do the actual deployment. Things add up. I just want to run my app and be done with it.
This is why started to look for alternatives. I came across fly.io and it sounded intriguing,
so I gave it a try. If you have your app "dockerized", deploying the app is almost as simple as installing the
fly.io cli tool and run: fly deploy. This will hang our app under the fly.dev domain. If your app name
is foo, it will be under foo.fly.dev. You can define different apps, maybe you want to have prod and dev envs
for the same app. You do so by using the -a flag when interacting with the fly.io cli tool. To create custom
domains, add a DNS A and AAAA entry to the ips that fly uses for your app (find that out by using: flyctl ips).Then create a cert with flyctl certs create app.mydomain.net.
The last pieces to get your app running is creating a volume to persist your sqlite db. We do so by using
flyctl volumes create. I believe you can have up to 3G for free. That is more than enough for most of
the things that I build. And that is pretty much it. When you run flyctl deploy the first time, the tool will
create a fly.toml file that keeps the fly configuration for the app. Remember to remove any references to the
app name so you can control that via the command line. That way you can deploy to different "apps".
The deployments are a bit slow for me right now. It takes about two minutes each time I deploy. This is because on each deploy we are rebuilding the docker images. I am sure there are ways to speed things up but I am ok with that for now.
drio out.